Subresource Integrity - Gecko Deep Dive
Last updated: Nov 30, 2020
Recently I’ve been doing code reviews of applications and have been recommending they take advantage of the security benefits that Subresource Integrity provides. This article will go into some detail about what it is and by analysing the Gecko source code some subtle nuances we can learn about it.
What and why?
I think an example would help illustrate the problem. When you navigate to a webpage, you initially perform a TCP Handshake on whichever Origin you attempt to navigate to.
After that, the webserver interprets your request and replies with a response. The response is split into headers and the payload. Generally, a html page is received and the HTML Elements are parsed by your browser to construct a DOM-Tree. This represents the structure of your website.
During parsing, the parser will sometimes encounter a resource that is linked to by the DOM-Tree. This is generally in the form of a script tag. The parser will pause parsing, then try to download and execute the script.
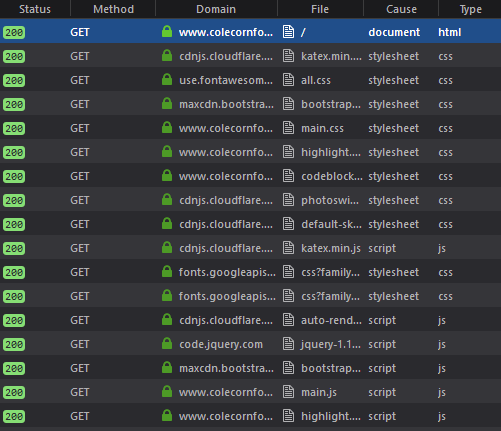
As you can see from this image, my website has a number of resources that are downloaded from third party domains. This is where subresource integrity (SRI) helps to mitigate security risk.
The Attack.
I use a Content-Security-Policy which gives me a level of security about which javascript code can be executed, and where it is allowed to come from.
<!DOCTYPE html>
<html lang="en" itemscope itemtype="http://schema.org/WebPage">
<head>
<meta http-equiv="Content-Security-Policy" content=" default-src 'self';
script-src 'self' 'unsafe-inline' https://cdnjs.cloudflare.com https://maxcdn.bootstrapcdn.com https://code.jquery.com https://cse.google.com https://prismjs.com;
style-src 'self' https://cdnjs.cloudflare.com https://use.fontawesome.com https://maxcdn.bootstrapcdn.com https://fonts.googleapis.com;
font-src 'self' https://use.fontawesome.com https://fonts.gstatic.com https://maxcdn.bootstrapcdn.com https://fonts.googleapis.com https://cdnjs.cloudflare.com https://maxcdn.bootstrapcdn.com;
connect-src 'self';
media-src 'none';
object-src 'none';
frame-src 'none';
worker-src 'none';
form-action 'self';
base-uri 'none';">
...
</head>
</html>
This partially protects my website and readers from loading malicious or unintended content. I have to specify exactly what I want my website to load.
The risk comes from being reliant on content delivery networks (CDN) for my CSS and JS files. I can host these locally, but in general, using a CDN will allow clients to take advantage of caching and local servers to reduce page load times.
If a CDN or its resources are compromised, then people may load malicious resources when navigating to sites using that CDN. SRI was developed to help with this scenario.
How does it work?
By adding an integrity attribute to an element, the browser can use it to verify the downloaded resource has not been tampered with. Currently, the integrity attribute is only supported by link and script tags.
<link rel="stylesheet" href="a.com/pretty.css"
integrity="sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u"
crossorigin="anonymous">
<script src="a.com/dothings.js"
integrity="sha384-K3vbOmF2BtaVai+Qk37uypf7VrgBubhQreNQe9aGsz9lB63dIFiQVlJbr92dw2Lx
sha512-Q2bFTOhEALkN8hOms2FKTDLy7eugP2zFZ1T8LCvX42Fp3WoNr3bjZSAHeOsHrbV1Fu9/A0EzCinRE7Af1ofPrw=="
crossorigin="anonymous"></script>
The integrity metadata is comprised of 2 parts (at the time of writing), the hashing algorithm and the base64 encoded hash of the resource (the digest). Each browser interprets the standard differently, so let’s start with how Firefox does it.
Gecko (Firefox)

Let’s walk through the SRI Implementation in Gecko, the firefox rendering engine. There are 3 files that we need to care about:
- SRIMetadata: Storing SRI Metadata and providing methods for interacting with it.
- SRICheck: Does all the heavy lifting between SRIMetadata objects.
- SRILogger: Logs all events and failures.
Of these, we will be analysing SRIMetadata and SRICheck. Logging is fairly boring. :p
Don’t worry if you have trouble understanding the C++ below, I’ve written about what matters in each one, and what we can glean from reading the source. So, the source is there if you want to dig in, but feel free to skim!
SRIMetadata Class Walkthrough
We’re starting with the SRIMetadata header file.
The header file shows that we have a limit of 256 hashes allowed per SRIMetadata, which should prevent DoS via hash overload. We also have a bunch of operators for working with SRIMetadata Objects, some methods for error checking, and accessors such as GetHash, GetAlgorithm, GetHashType, and GetIntegrityString.
class SRIMetadata final {
friend class SRICheck;
public:
static const uint32_t MAX_ALTERNATE_HASHES = 256;
static const int8_t UNKNOWN_ALGORITHM = -1;
SRIMetadata() : mAlgorithmType(UNKNOWN_ALGORITHM), mEmpty(true) {}
explicit SRIMetadata(const nsACString& aToken);
bool operator<(const SRIMetadata& aOther) const;
bool operator>(const SRIMetadata& aOther) const;
SRIMetadata& operator+=(const SRIMetadata& aOther);
bool operator==(const SRIMetadata& aOther) const;
bool IsEmpty() const { return mEmpty; }
bool IsMalformed() const { return mHashes.IsEmpty() || mAlgorithm.IsEmpty(); }
bool IsAlgorithmSupported() const {return mAlgorithmType != UNKNOWN_ALGORITHM; }
bool IsValid() const { return !IsMalformed() && IsAlgorithmSupported(); }
uint32_t HashCount() const { return mHashes.Length(); }
void GetHash(uint32_t aIndex, nsCString* outHash) const;
void GetAlgorithm(nsCString* outAlg) const { *outAlg = mAlgorithm; }
void GetHashType(int8_t* outType, uint32_t* outLength) const;
const nsString& GetIntegrityString() const { return mIntegrityString; }
private:
nsTArray<nsCString> mHashes;
nsString mIntegrityString;
nsCString mAlgorithm;
int8_t mAlgorithmType;
bool mEmpty;
};
SRIMetadata gets instantiated with the string value provided to the element. We validate that token, and then add it to the mHashes array.
Mozilla has elected to allow for options as part of their spec, even though at this stage the W3 Specification states that there are currently no options available for use.
Below we have the operators for SRIMetadata objects.
bool SRIMetadata::operator<(const SRIMetadata& aOther) const {
static_assert(nsICryptoHash::SHA256 < nsICryptoHash::SHA384,
"We rely on the order indicating relative alg strength");
static_assert(nsICryptoHash::SHA384 < nsICryptoHash::SHA512,
"We rely on the order indicating relative alg strength");
MOZ_ASSERT(mAlgorithmType == SRIMetadata::UNKNOWN_ALGORITHM ||
mAlgorithmType == nsICryptoHash::SHA256 ||
mAlgorithmType == nsICryptoHash::SHA384 ||
mAlgorithmType == nsICryptoHash::SHA512);
MOZ_ASSERT(aOther.mAlgorithmType == SRIMetadata::UNKNOWN_ALGORITHM ||
aOther.mAlgorithmType == nsICryptoHash::SHA256 ||
aOther.mAlgorithmType == nsICryptoHash::SHA384 ||
aOther.mAlgorithmType == nsICryptoHash::SHA512);
if (mEmpty) {
SRIMETADATALOG(("SRIMetadata::operator<, first metadata is empty"));
return true; // anything beats the empty metadata (incl. invalid ones)
}
SRIMETADATALOG(("SRIMetadata::operator<, alg1='%d'; alg2='%d'",
mAlgorithmType, aOther.mAlgorithmType));
return (mAlgorithmType < aOther.mAlgorithmType);
}
bool SRIMetadata::operator>(const SRIMetadata& aOther) const {
MOZ_ASSERT(false);
return false;
}
SRIMetadata& SRIMetadata::operator+=(const SRIMetadata& aOther) {
MOZ_ASSERT(!aOther.IsEmpty() && !IsEmpty());
MOZ_ASSERT(aOther.IsValid() && IsValid());
MOZ_ASSERT(mAlgorithmType == aOther.mAlgorithmType);
// We only pull in the first element of the other metadata
MOZ_ASSERT(aOther.mHashes.Length() == 1);
if (mHashes.Length() < SRIMetadata::MAX_ALTERNATE_HASHES) {
SRIMETADATALOG((
"SRIMetadata::operator+=, appending another '%s' hash (new length=%zu)",
mAlgorithm.get(), mHashes.Length()));
mHashes.AppendElement(aOther.mHashes[0]);
}
MOZ_ASSERT(mHashes.Length() > 1);
MOZ_ASSERT(mHashes.Length() <= SRIMetadata::MAX_ALTERNATE_HASHES);
return *this;
}
bool SRIMetadata::operator==(const SRIMetadata& aOther) const {
if (IsEmpty() || !IsValid()) {
return false;
}
return mAlgorithmType == aOther.mAlgorithmType;
}
The most important operators are += and <. We use += to add another hash to the list of hashes. This is notable. It means that we can specify multiple hashes for a single resource.
In the < operator, Mozilla asserts that Empty < SHA256 < SHA384 < SHA512. This is then used to compare the strength of two SRIMetadata algorithms and return true or false. Of note, the only algorithms supported are SHA256/384/512.
This is interesting. If you specify something like MD5 or SHA1, then the integrity tag is likely to provide No Security Benefit
The last part of SRIMetadata are the Getters. Some are simple and defined in the headers already, but they’re mostly self-explanatory.
void SRIMetadata::GetHash(uint32_t aIndex, nsCString* outHash) const {
MOZ_ASSERT(aIndex < SRIMetadata::MAX_ALTERNATE_HASHES);
if (NS_WARN_IF(aIndex >= mHashes.Length())) {
*outHash = nullptr;
return;
}
*outHash = mHashes[aIndex];
}
void SRIMetadata::GetHashType(int8_t* outType, uint32_t* outLength) const {
// these constants are defined in security/nss/lib/util/hasht.h and
// netwerk/base/public/nsICryptoHash.idl
switch (mAlgorithmType) {
case nsICryptoHash::SHA256:
*outLength = SHA256_LENGTH;
break;
case nsICryptoHash::SHA384:
*outLength = SHA384_LENGTH;
break;
case nsICryptoHash::SHA512:
*outLength = SHA512_LENGTH;
break;
default:
*outLength = 0;
}
*outType = mAlgorithmType;
}
SRICheck Walkthrough
Still with me? Next up is SRICheck, the actual comparison method. Here’s the header file. What sticks out to me is that there are two methods for verifying tokens.
Why would you want two methods? The first method is absolutely required to function from a clean slate. The second method is called when a hash has already been pre-computed. This was written to save the client additional processing, and to prevent downloading of additional files if we already have hash metadata that tells us not to.
I’ll only look at the streaming method to keep this post concise since it’s long already.
class SRIMetadata;
class SRICheck final {
public:
static const uint32_t MAX_METADATA_LENGTH = 24 * 1024;
static const uint32_t MAX_METADATA_TOKENS = 512;
static nsresult IntegrityMetadata(const nsAString& aMetadataList, const nsACString& aSourceFileURI, nsIConsoleReportCollector* aReporter, SRIMetadata* outMetadata);
};
class SRICheckDataVerifier final {
public:
SRICheckDataVerifier(const SRIMetadata& aMetadata,const nsACString& aSourceFileURI, nsIConsoleReportCollector* aReporter);
// Method 1
nsresult Update(uint32_t aStringLen, const uint8_t* aString);
nsresult Verify(const SRIMetadata& aMetadata, nsIChannel* aChannel, const nsACString& aSourceFileURI, nsIConsoleReportCollector* aReporter);
bool IsComplete() const { return mComplete; }
// Method 2
uint32_t DataSummaryLength();
static uint32_t EmptyDataSummaryLength();
nsresult ExportDataSummary(uint32_t aDataLen, uint8_t* aData);
static nsresult ExportEmptyDataSummary(uint32_t aDataLen, uint8_t* aData);
static nsresult DataSummaryLength(uint32_t aDataLen, const int8_t* aData, uint32_t* length);
nsresult ImportDataSummary(uint32_t aDataLen, const uint8_t* aData);
private:
nsCOMPtr<nsICryptoHash> mCryptoHash;
nsAutoCString mComputedHash;
size_t mBytesHashed;
uint32_t mHashLength;
int8_t mHashType;
bool mInvalidMetadata;
bool mComplete;
nsresult EnsureCryptoHash();
nsresult Finish();
nsresult VerifyHash(const SRIMetadata& aMetadata, uint32_t aHashIndex, const nsACString& aSourceFileURI, nsIConsoleReportCollector* aReporter);
};
We initially check that the resource is eligible for SRI. It must not violate Same-Origin Policy. If it is ineligible, SRI will be redundant since we will not be loading the resource anyway.
Compared to Blink and Webkit, Gecko has been written with defensive coding at the forefront. Mozilla truncates really long pieces of metadata, checks for malformed metadata, and ignores unsupported algorithms (!). Funnily, users can disable SRI in their browser preferences, which Gecko accepts.
I’ve removed a bunch of complexity from the code below, but basically we’re checking for a stronger algorithm, if it exists we start again. Then we’re checking for an equal algorithm, and if we are equal, we add our new hash to the list.
nsresult SRICheck::IntegrityMetadata(const nsAString& aMetadataList, const nsACString& aSourceFileURI, nsIConsoleReportCollector* aReporter, SRIMetadata* outMetadata) {
... // Validation Code of metadata
nsAutoCString alg1, alg2;
if (MOZ_LOG_TEST(SRILogHelper::GetSriLog(), mozilla::LogLevel::Debug)) {
outMetadata->GetAlgorithm(&alg1);
metadata.GetAlgorithm(&alg2);
}
if (*outMetadata == metadata) {
SRILOG(("SRICheck::IntegrityMetadata, alg '%s' is the same as '%s'",
alg1.get(), alg2.get()));
*outMetadata += metadata; // add new hash to strongest metadata
} else if (*outMetadata < metadata) {
SRILOG(("SRICheck::IntegrityMetadata, alg '%s' is weaker than '%s'",
alg1.get(), alg2.get()));
*outMetadata = metadata; // replace strongest metadata with current
}
outMetadata->mIntegrityString = aMetadataList;
... // Validation Code of aMetadataList
return NS_OK;
}
Another Very Important thing we discovered here. We can specify multiple hashes that use the same algorithm for any particular resource. When would this come up? Version and cache control! Check this out.
<script src="https://cdn.colecornford.com/latest-discipline.js"
integrity="sha384-Li9vy3DqF8tnTXuiaAJuML3ky+er10rcgNR/VqsVpcw+ThHmYcwiB1pbOxEbzJr7
sha384-+/M6kredJcxdsqkczBUjMLvqyHb1K/JThDXWsBVxMEeZHEaMKEOEct339VItX1zB"
crossorigin="anonymous"></script>
If we decide to update latest-discipline.js then we can specify two hashes, one for the old file and one for the new one. This matters if a user has cached your old javascript file locally, or you are using a CDN and are unable to purge or invalidate the file from some of your edge servers. We want users to still be able to use the site, and to maintain security, so we specify both the old file’s hash, and the new one too.
This list of hashes (mCryptoHash) is made by reading a stream of bytes and adding the hashes to mCryptoHash while keeping track of mBytesHashed. Each time a new hash is compared, we call Update until we have our full list of strongHashes calculated.
nsresult SRICheckDataVerifier::Update(uint32_t aStringLen,
const uint8_t* aString) {
NS_ENSURE_ARG_POINTER(aString);
if (mInvalidMetadata) {
return NS_OK; // ignoring any data updates, see mInvalidMetadata usage
}
nsresult rv;
rv = EnsureCryptoHash();
NS_ENSURE_SUCCESS(rv, rv);
mBytesHashed += aStringLen;
return mCryptoHash->Update(aString, aStringLen);
}
nsresult SRICheckDataVerifier::Finish() {
if (mInvalidMetadata || mComplete) {
return NS_OK; // already finished or invalid metadata
}
nsresult rv;
rv = EnsureCryptoHash(); // we need computed hash even for 0-length data
NS_ENSURE_SUCCESS(rv, rv);
rv = mCryptoHash->Finish(false, mComputedHash);
mCryptoHash = nullptr;
mComplete = true;
return rv;
}
The Verification process is very simple in comparison to the rest of the program. When we get to the stage to verify the hash, we check to see if the resource complies with Same-Origin Policy. We then loop through every hash and run VerifyHash (talked about further below). If we don’t get a succesful verification, then SRI has failed, and the resource will not be loaded.
nsresult SRICheckDataVerifier::Verify(const SRIMetadata& aMetadata,
nsIChannel* aChannel,
const nsACString& aSourceFileURI,
nsIConsoleReportCollector* aReporter) {
NS_ENSURE_ARG_POINTER(aReporter);
if (MOZ_LOG_TEST(SRILogHelper::GetSriLog(), mozilla::LogLevel::Debug)) {
nsAutoCString requestURL;
nsCOMPtr<nsIRequest> request = aChannel;
request->GetName(requestURL);
SRILOG(("SRICheckDataVerifier::Verify, url=%s (length=%zu)",
requestURL.get(), mBytesHashed));
}
nsresult rv = Finish();
NS_ENSURE_SUCCESS(rv, rv);
nsCOMPtr<nsILoadInfo> loadInfo = aChannel->LoadInfo();
LoadTainting tainting = loadInfo->GetTainting();
if (NS_FAILED(IsEligible(aChannel, tainting, aSourceFileURI, aReporter))) {
return NS_ERROR_SRI_NOT_ELIGIBLE;
}
if (mInvalidMetadata) {
return NS_OK; // ignore invalid metadata for forward-compatibility
}
for (uint32_t i = 0; i < aMetadata.HashCount(); i++) {
if (NS_SUCCEEDED(VerifyHash(aMetadata, i, aSourceFileURI, aReporter))) {
return NS_OK; // stop at the first valid hash
}
}
nsAutoCString alg;
aMetadata.GetAlgorithm(&alg);
NS_ConvertUTF8toUTF16 algUTF16(alg);
nsTArray<nsString> params;
params.AppendElement(algUTF16);
aReporter->AddConsoleReport(
nsIScriptError::errorFlag, NS_LITERAL_CSTRING("Sub-resource Integrity"),
nsContentUtils::eSECURITY_PROPERTIES, aSourceFileURI, 0, 0,
NS_LITERAL_CSTRING("IntegrityMismatch"),
const_cast<const nsTArray<nsString>&>(params));
return NS_ERROR_SRI_CORRUPT;
}
When we receive a hash, we base64 decode it. If it fails to decode, we move on to the next hash. We use Moz’s built in crypto functions to validate the computed hash against the specified one. If it fails, we move to next hash, if it passes we exit succesfully and load the resource.
nsresult SRICheckDataVerifier::VerifyHash(
const SRIMetadata& aMetadata, uint32_t aHashIndex,
const nsACString& aSourceFileURI, nsIConsoleReportCollector* aReporter) {
NS_ENSURE_ARG_POINTER(aReporter);
... // Base64 Validation Code
if (MOZ_LOG_TEST(SRILogHelper::GetSriLog(), mozilla::LogLevel::Debug)) {
nsAutoCString encodedHash;
nsresult rv = Base64Encode(mComputedHash, encodedHash);
if (NS_SUCCEEDED(rv)) {
SRILOG(("SRICheckDataVerifier::VerifyHash, mComputedHash=%s",
encodedHash.get()));
}
}
if (!binaryHash.Equals(mComputedHash)) {
SRILOG(("SRICheckDataVerifier::VerifyHash, hash[%u] did not match",
aHashIndex));
return NS_ERROR_SRI_CORRUPT;
}
SRILOG(("SRICheckDataVerifier::VerifyHash, hash[%u] verified successfully",
aHashIndex));
return NS_OK;
}
Closing Thoughts
That’s a deep dive into how Gecko does SRI. Browsers are tremendously complex beasts with many moving parts. But by going into the source code, we learned a few important things about how Firefox manages SRI.
-
We can specify multiple hashes
-
We can specify multiple hashes of different algorithm types. The hash generated by the strongest algorithm is used for verification.
-
We can specify multiple hashes of the same algorithm type. All hashes are used for verification, if any succeed the resource is loaded.
-
Users can turn off SRI in browser preferences.
-
It only works for Link and Script tags right now. But I have hope that fonts, images, and everything else will be available in the future.
-
Same-Origin is always checked before SRI is attempted.
-
There are boundary checks on both the size of a given hash, and also on the number of hashes the program will load.
-
Any algorithm that is not SHA256/SHA384/SHA512 throws an unsupported algorithm warning and will result in unexpected behaviour, erring on the side of usability.
-
The CSP directive of require-sri-for is evaluated within the CSP section of Gecko, not within SRI itself.
-
Mozilla are kick ass at defensive coding.
Thanks for reading friends, hope this deep dive has been helpful for you.
Cole Cornford
Full source of Gecko available here